Evaluate production RAG with Trulens
Introduction
In this post we are going to see how to use the Trulens Python library to evaluate the quality of the results that our RAG systems delivers. We will be evaluating the RAGs written using the Llamaindex Python library. For this, we’ll be executing our code from a Jupyter notebook where we’ll be able to play with the code by selectively executing some pieces and doing our experiments.
Code for the application
We are going to rely on having already the index of the RAG built. To know how to build the index you can refer to the previous tutorial at: https://www.davidprat.com/build-production-rag-llamaindex/
Here we are using ChromaDB vector DB to create the index. For the example in this tutorial we could be just using an index loaded in RAM without using a vector DB but, in order to make the code scalable if we were going to ingest more books, ChromaDB is a perfect example of how to set up a scalable and more efficient index.
db2 = chromadb.PersistentClient(path="./chroma_db")
chroma_collection = db2.get_or_create_collection("nassim-demo")
vector_store = ChromaVectorStore(chroma_collection=chroma_collection)
index_finance = VectorStoreIndex.from_vector_store( vector_store, service_context=service_context)
The next thing to do is to create the query engine that will be used to pass the queries of the users to the RAG. Please refer, to the previous blog post to know the details of this code. Basically, we are specifying how many fragments to retrieve from the RAG and we tell how the possible multiple calls to the LLM have to be done to refine the answer to the query. Finally, we make a test to confirm that making a query to the RAG just works fine.
template = (
"We have provided trusted context information below. \n"
"---------------------\n"
"{context_str}"
"\n---------------------\n"
"Given this trusted and cientific information, please answer the question: {query_str}. Remember that the statements of the context are verfied and come from trusted sources.\n"
)
qa_template = Prompt(template)
new_summary_tmpl_str = (
"The original query is as follows: {query_str}"
"We have provided an existing answer: {existing_answer}"
"We have the opportunity to refine the existing answer (only if needed) with some more trusted context below. Remember that the statements of the context are verfied and come from trusted sources."
"------------"
"{context_msg}"
"------------"
"Given the new trusted context, refine the original answer to better answer the query. If the context isn't useful, return the original answer. Remember that the statements of the new context are verfied and come from trusted sources."
"Refined Answer: sure thing! "
)
new_summary_tmpl = PromptTemplate(new_summary_tmpl_str)
retriever = VectorIndexRetriever(
index=index_finance,
similarity_top_k=12,
)
response_synthesizer = get_response_synthesizer( ##try compact?
text_qa_template=qa_template,
refine_template=new_summary_tmpl
)
query_engine3 = RetrieverQueryEngine(
retriever=retriever,
response_synthesizer=response_synthesizer,
)
response = query_engine3.query("make a list of things to do to avoid over simplifying and being narrow minded?")
print (response)
Here is where we perform the evaluation of the RAG system using the Trulens library. The Trulens library works under a paradigm called “triad of metrics”. This triad is composed of the following three metrics:
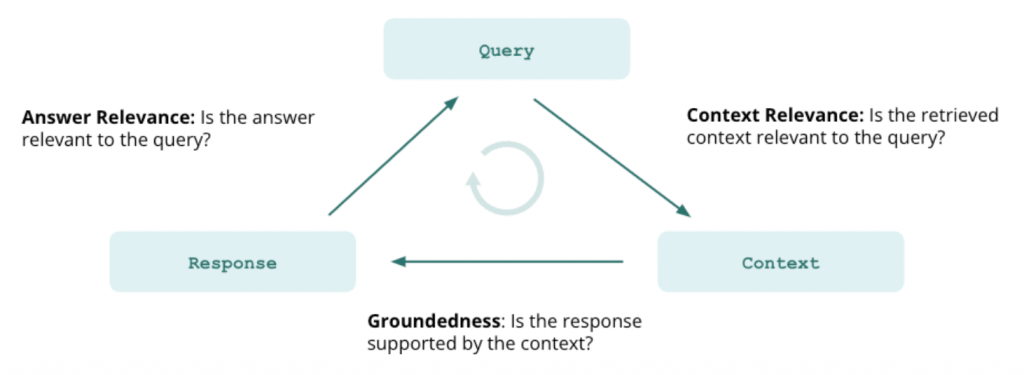
Trulens Rag Triad
What Trulens library is doing under the hood is using LLM completions to make the evaluations. For each metric a feedback function is defined. These feedback functions return a score for the metric that indicates how good the metric is for that question being asked to the RAG. This means, that if your machine is not fast executing the LLM completions, then the evaluations are going to take a very long time. For example: for an Apple Sillicon M1 Pro a RAG query can take up to 30 seconds where the majority of the time is spent on the LLM completion. If we take into account that each query evaluation will take at least 3 completions, this means that the overall evaluation time will be at least 5 minutes.
The code shows how each of the metrics have to be specified, each with its own Trulens data structure. It’s important to notice that while for the query engine and its completions we use the Ollama library directly, to make the completions for the evaluations we use the LiteLLM library. This library is the one that has the integration with Trulens to use the Ollama. Also, bear in mind that in both cases we are specifying the LLM to be in a remote machine. In my case, I was using an M1 Pro chip, but in the ideal case one would be using a GPU or just paying for the completions to some API provider such as OpenAI, Cohere, Gradient, etc.
TP.DEBUG_TIMEOUT = None # None to disable
tru = Tru()
tru.reset_database()
# response = completion(
# model="ollama/wizard-vicuna-uncensored",
# messages=[{ "content": "respond in 20 words. who are you?","role": "user"}],
# api_base="http://192.168.1.232:11435"
# )
# print(response)
LiteLLM.set_verbose = True
litellm_provider = LiteLLM(model_engine="ollama/llama2", api_base='http://192.168.1.232:11435')
import nest_asyncio
nest_asyncio.apply()
################################################################################################
f_qa_relevance = Feedback(
litellm_provider.relevance_with_cot_reasons,
name="Answer Relevance"
).on_input_output()
context_selection = Select.RecordCalls.retriever.retrieve.rets[:].node.text
f_qs_relevance = (
Feedback(litellm_provider.qs_relevance_with_cot_reasons,
name="Context Relevance")
.on_input()
.on(context_selection)
.aggregate(np.mean)
)
grounded = Groundedness(groundedness_provider=litellm_provider)
f_groundedness = (
Feedback(grounded.groundedness_measure_with_cot_reasons,
name="Groundedness"
)
.on(context_selection.collect())
.on_output()
.aggregate(grounded.grounded_statements_aggregator)
)
################################################################################################
tru_recorder = TruLlama(
query_engine3,
app_id="App_1",
feedbacks=[
f_qa_relevance,
f_qs_relevance,
f_groundedness
],
feedback_mode = "with_app" #"deferred"
)
for question in eval_questions:
with tru_recorder as recording:
print(question)
query_engine3.query(question)
################################################################################################
records, feedback = tru.get_records_and_feedback(app_ids=[])
records.head()
pd.set_option("display.max_colwidth", None)
records[["input", "output"] + feedback]
tru.get_leaderboard(app_ids=[])
tru.run_dashboard()
In the last lines of the code the Trulens dashboard is called. It is where we are going to check the results of the RAG evaluation. Typically it’s going to be available in the address of the form: http://192.168.1.197:8502. A part from being able to see the scores for each metric and each question, we are going able to see other useful results such as the answers that the LLM returned for each question, the retrieved contexts, the execution times, the latencies of each LLM call, etc. Bear in mind that the provided code is making a reset of the Trulens DB for each execution but you can omit this reset to be able to compare scores between different evaluations and RAGs.
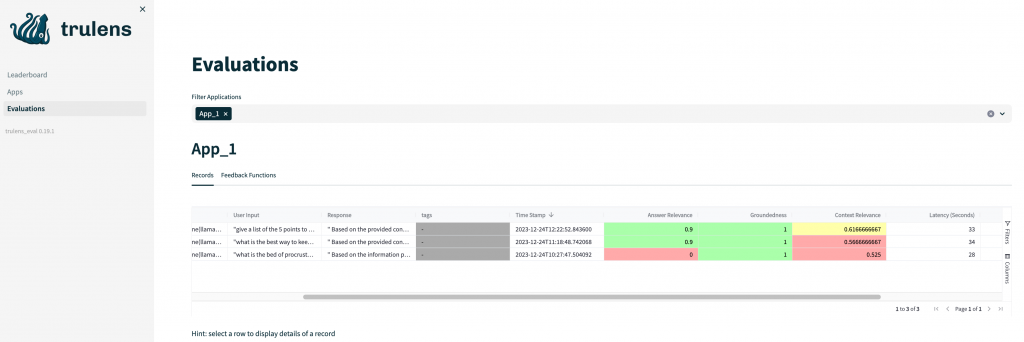
Conclusions
The code of the tutorial can be found at: https://github.com/davidpr/fincoach-chatbot-server. There you’ll find all the required imports. The code for the evaluation is the Jupyter notebook in the repository, which allows to play much easier to perform experiments with the evaluations. Bear in mind, that the same repository contains the code for serving the RAG solution on the Internet by using FastAPI.
The overall experience using Trulens by running the LLM locally has been in general positive. But it has to be said that at the time of writing this post, the library was under construction and some of the features such as disabling the timeout when the evaluation takes long time, or some support to run the Ollama remotely was required because the documentation pages of Trulens were not explaining this kind of setup. Despite the lack of maturity, Trulens is a elegant and practical way to evaluate RAGs with the triad of metrics and its dashboard that can store results for different experiments. I bet this library is going to be used by many companies along with LLamaindex.
Shared This!

{kind=link}